mirror of
https://codeberg.org/forgejo/forgejo
synced 2024-11-29 21:26:10 +01:00
5 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
9df10c5ac5
|
[FEAT] Only implement used API of Redis client
- Currently for the `nosql` module (which simply said provides a manager for redis clients) returns the [`redis.UniversalClient`](https://pkg.go.dev/github.com/redis/go-redis/v9#UniversalClient) interface. The interfaces exposes all available commands. - In generalm, dead code elimination should be able to take care of not generating the machine code for methods that aren't being used. However in this specific case, dead code elimination either is disabled or gives up on trying because of exhaustive call stack the client by `GetRedisClient` is used. - Help the Go compiler by explicitly specifying which methods we use. This reduces the binary size by ~400KB (397312 bytes). As Go no longer generate machine code for commands that aren't being used. - There's a **CAVEAT** with this, if a developer wants to use a new method that isn't specified, they will have to know about this hack (by following the definition of existing Redis methods) and add the method definition from the Redis library to the `RedisClient` interface. |
||
|
|
54acfa8880
|
refactor: redis queue backend test cleanup
Summary:
- Move existing test under a `testify` Suite as `baseRedisWithServerTestSuite`
- Those tests require real redis server.
- Add `go.uber.org/mock/mockgen@latest` as dependency
- as a tool (Makefile).
- in the `go.mod` file.
- Mock redis client lives under a `mock` directory under the queue module.
- That mock module has an extra hand-written mock in-memory redis-like struct.
- Add tests using the mock redis client.
- Changed the logic around queue provider creation.
- Now the `getNewQueue` returns a Queue provider directly, not an init
function to create it.
The whole Queue module is close to impossible to test properly because
everything is private, everything goes through a struct route. Because
of that, we can't test for example what keys are used for given queue.
To overcome this, as a first step I removed one step from that hard
route by allowing custom calls to create new queue provider. To achieve
this, I moved the creation logic into the `getNewQueue` (previously it
was `getNewQueueFn`). That changes nothing on that side, everything goes
as before, except the `newXXX` call happens directly in that function
and not outside that.
That made it possible to add extra provider specific parameters to those
function (`newXXX`). For example a client on redis. Calling it through
the `getNewQueue` function, it gets `nil`.
- If the provided client is not `nil`, it will use that instead of the
connection string.
- If it's `nil` (default behaviour), it creates a new redis client as it
did before, no changes to that.
The rest of the provider code is unchanged. All these changes were
required to make it possible to generate mock clients for providers and
use them.
For the tests, the existing two test cases are good with redis server,
and they need some extra helpers, for example to start a new redis
server if required, or waiting on a redis server to be ready to use.
These helpers are only required for test cases using real redis server.
For better isolation, moved existing test under a testify Suite, and
moved them into a new test file called `base_redis_with_server_test.go`
because, well they test the code with server. These tests do exactly the
same as before, calling the same sub-tests the same way as before, the
only change is the structure of the test (remove repetition, scope
server related helper functions).
Finally, we can create unit tests without redis server. The main focus of
this group of tests are higher level overview of operations. With the
mock redis client we can set up expectations about used queue names,
received values, return value to simulate faulty state.
These new unit test functions don't test all functionality, at least
it's not aimed for it now. It's more about the possibility of doing that
and add extra tests around parts we couldn't test before, for example
key.
What extra features can test the new unit test group:
- What is the received key for given queue? For example using `prefix`,
or if all the `SXxx` calls are expected to use `queue_unique` if
it's a unique queue.
- If it's not a unique queue, no `SXxx` functions are called, because
those sets are used only to check if a value is unique or not.
- `HasItem` return `false` always if it's a non-unique queue.
- All functions are called exactly `N` times, and we don't have any
unexpected calls to redis from the code.
Signed-off-by: Victoria Nadasdi <victoria@efertone.me>
|
||
|
|
df0d1a2134 |
feat: parse prefix from redis URI for queues (#3836)
For security reasons, scoping access to a redis server via ACL rules is a good practice. Some parts of the codebase handles prefix like cache[^1] and session[^2], but the queue module doesn't. This patch adds this missing functionality to the queue module. Note about relevant test: I tried to keep the PR as small as possible (and reasonable), and not change how the test runs. Updated the existing test to use the same redis address and basically duplicated the test with the extra flag. It does NOT test if the keys are correct, it ensures only it works as expected. To make assertions about the keys, the whole test has to be updated as the general wrapper doesn't allow the main test to check anything provider (redis) specific property. That's not something I wanted to take on now. [^1]: |
||
|
|
58dfaf3a75
|
Improve queue & process & stacktrace (#24636)
Although some features are mixed together in this PR, this PR is not
that large, and these features are all related.
Actually there are more than 70 lines are for a toy "test queue", so
this PR is quite simple.
Major features:
1. Allow site admin to clear a queue (remove all items in a queue)
* Because there is no transaction, the "unique queue" could be corrupted
in rare cases, that's unfixable.
* eg: the item is in the "set" but not in the "list", so the item would
never be able to be pushed into the queue.
* Now site admin could simply clear the queue, then everything becomes
correct, the lost items could be re-pushed into queue by future
operations.
3. Split the "admin/monitor" to separate pages
4. Allow to download diagnosis report
* In history, there were many users reporting that Gitea queue gets
stuck, or Gitea's CPU is 100%
* With diagnosis report, maintainers could know what happens clearly
The diagnosis report sample:
[gitea-diagnosis-20230510-192913.zip](https://github.com/go-gitea/gitea/files/11441346/gitea-diagnosis-20230510-192913.zip)
, use "go tool pprof profile.dat" to view the report.
Screenshots:
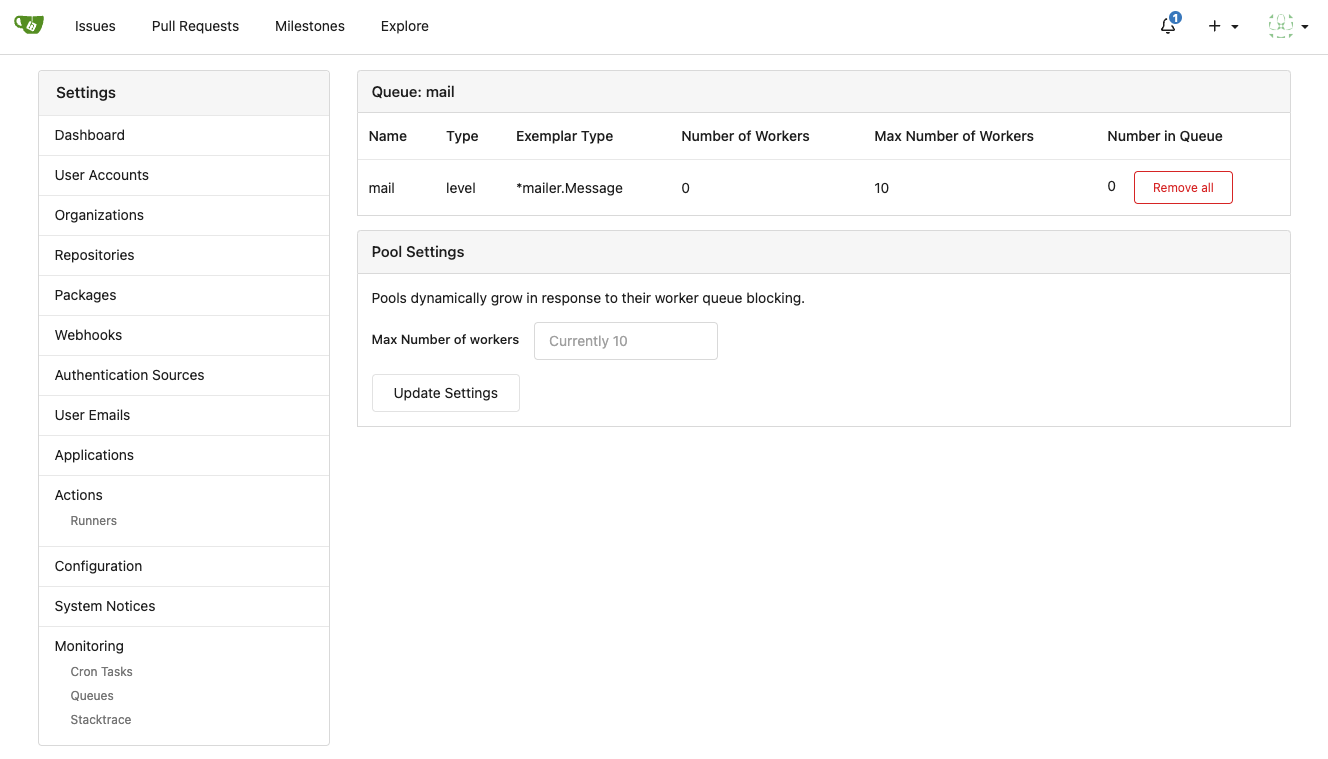
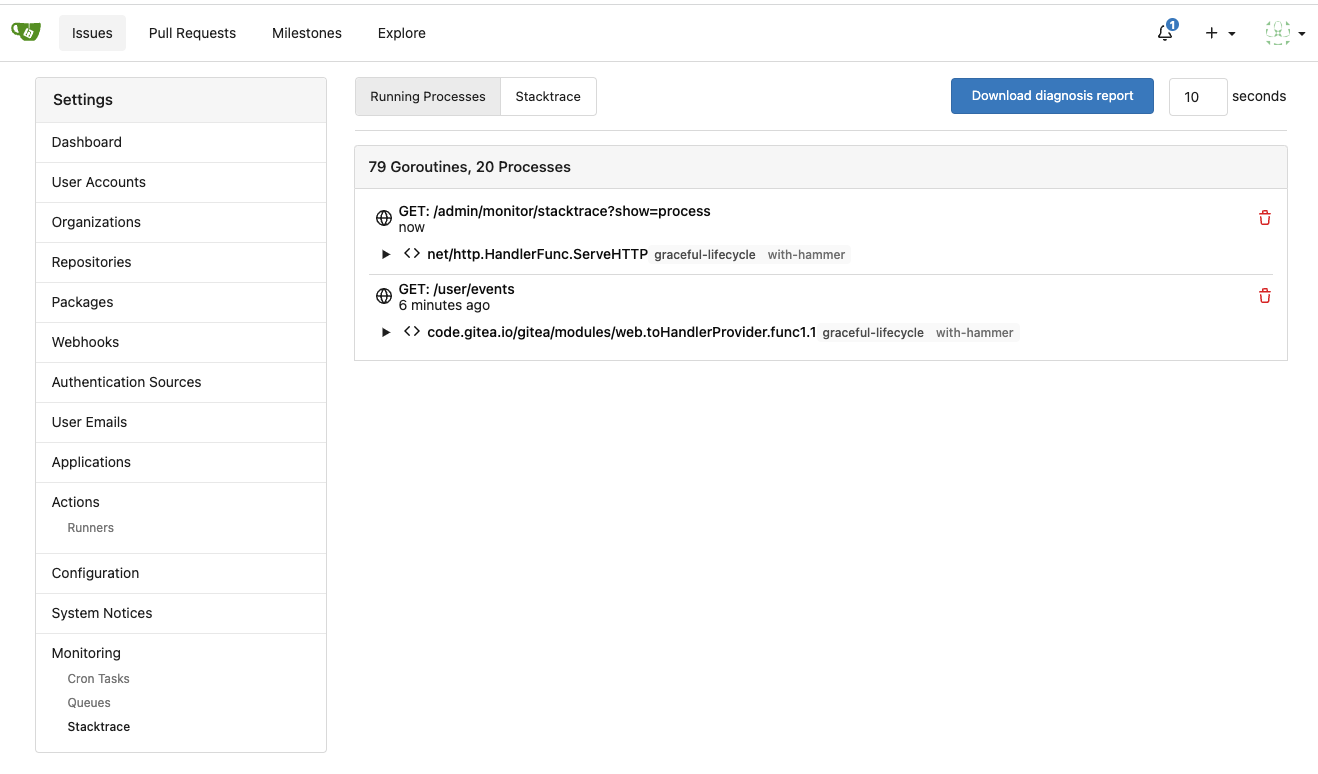

---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Giteabot <teabot@gitea.io>
|
||
|
|
6f9c278559
|
Rewrite queue (#24505)
# ⚠️ Breaking Many deprecated queue config options are removed (actually, they should have been removed in 1.18/1.19). If you see the fatal message when starting Gitea: "Please update your app.ini to remove deprecated config options", please follow the error messages to remove these options from your app.ini. Example: ``` 2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]` 2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]` 2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options ``` Many options in `[queue]` are are dropped, including: `WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`, `BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed from app.ini. # The problem The old queue package has some legacy problems: * complexity: I doubt few people could tell how it works. * maintainability: Too many channels and mutex/cond are mixed together, too many different structs/interfaces depends each other. * stability: due to the complexity & maintainability, sometimes there are strange bugs and difficult to debug, and some code doesn't have test (indeed some code is difficult to test because a lot of things are mixed together). * general applicability: although it is called "queue", its behavior is not a well-known queue. * scalability: it doesn't seem easy to make it work with a cluster without breaking its behaviors. It came from some very old code to "avoid breaking", however, its technical debt is too heavy now. It's a good time to introduce a better "queue" package. # The new queue package It keeps using old config and concept as much as possible. * It only contains two major kinds of concepts: * The "base queue": channel, levelqueue, redis * They have the same abstraction, the same interface, and they are tested by the same testing code. * The "WokerPoolQueue", it uses the "base queue" to provide "worker pool" function, calls the "handler" to process the data in the base queue. * The new code doesn't do "PushBack" * Think about a queue with many workers, the "PushBack" can't guarantee the order for re-queued unhandled items, so in new code it just does "normal push" * The new code doesn't do "pause/resume" * The "pause/resume" was designed to handle some handler's failure: eg: document indexer (elasticsearch) is down * If a queue is paused for long time, either the producers blocks or the new items are dropped. * The new code doesn't do such "pause/resume" trick, it's not a common queue's behavior and it doesn't help much. * If there are unhandled items, the "push" function just blocks for a few seconds and then re-queue them and retry. * The new code doesn't do "worker booster" * Gitea's queue's handlers are light functions, the cost is only the go-routine, so it doesn't make sense to "boost" them. * The new code only use "max worker number" to limit the concurrent workers. * The new "Push" never blocks forever * Instead of creating more and more blocking goroutines, return an error is more friendly to the server and to the end user. There are more details in code comments: eg: the "Flush" problem, the strange "code.index" hanging problem, the "immediate" queue problem. Almost ready for review. TODO: * [x] add some necessary comments during review * [x] add some more tests if necessary * [x] update documents and config options * [x] test max worker / active worker * [x] re-run the CI tasks to see whether any test is flaky * [x] improve the `handleOldLengthConfiguration` to provide more friendly messages * [x] fine tune default config values (eg: length?) ## Code coverage:  |
{kind=link}